はじめに
カルマンフィルター(1),(2)に続いて本エントリーでは、非線形なモデルに対してカルマンフィルターを用いるための方法についてまとめます。本稿で述べる内容については、線形モデルの場合のカルマンフィルターの理解を前提とします。線形モデルの場合のカルマンフィルターについては、過去にまとめておりますのでこちらも是非ご覧下さい。
具体的には、非線形モデルを線形近似する拡張カルマンフィルター(Extended Kalman FIlter : EKF)およびサンプル点を用いて分布を近似する無香カルマンフィルター(Unscented Kalman Filter:UKF)について紹介します。EKFの解説については、日本語の記事もネット上に豊富なので本記事ではどちらかというとUKFの解説に重きを置きたいと思います。
非線形なモデル
以前のエントリーで紹介したとおり、一般のカルマンフィルターでは予測モデルと更新モデルの両方が状態量と制御入力、観測に対して線形のモデルである事を前提に時刻$t$における平均と分散およびカルマンゲインを求める式を導出することが出来ました。ここでは線形でないモデルを考えて、その場合の平均と分散およびカルマンゲインを求める式を導出します。
非線形モデル:
ここで、$\bf{u_t}$は制御入力、${ \bf G}_t$はノイズのモデル式で${ \bf w}_t$と${ \bf v}_t$はそれぞれ式(3),(4)の通り分散共分散行列がそれぞれ$Q_t$と$R_t$の多正規分布に従うノイズです。また、$\bf{y_t},\bf{z_t},\bf{u_t}$と${ \bf w}_t$と${ \bf v}_t$および${ \bf w}_t$と${ \bf v}_t$同士はtによらず独立であるとします。
EKF
EKFのアイデアはシンプルで、非線形な(1)と(2)も局所的に見ると線形な関数と近似できるのでその近似式さえ求まれば後は通常のKFと同様に扱えるというものです。数学的にはTaylor展開した上で、2次の項以降を無視します。
式(1)・(2)の線形化:
式(1)と(2)において$f(\bf{y_{t-1}},\bf{u_t})$と$g(\bf{y_{t}})$を$\bf{\hat{y}_{t-1|t-1}}$の周りでTaylor展開し、2次の項移行を無視します。
ここで${ \bf F_t,H_t }$はJacobianであり、以下で表されます。
この関係式を用いて以下は予測モデルと更新モデルの期待値と分散の式を導出します。考え方は線形の場合と同様です。時刻:$t$において得られている情報:$I_t$を使って条件付き確率の期待値・分散として計算します。
予測モデル:
更新モデル:
ここで${ \bf C,S}$は以下で表される。これも線形の場合と変わりません。
以上まとめるとEKFの予測・更新の式は以下の様になります。
予測:
更新:
但し、
UKF
EKFの課題として、線形化する一点のみの局所的な傾きの情報のみで変換後の分布を決めてしまうので、非線形性が強い場合誤差が大きくなってしまうという課題があります。そこで提案されたのがUKFでEKFと異なり一点のみではなくシグマ点という複数の点を抽出し、それらすべてを使って変換後の分布を求めます(図1)。
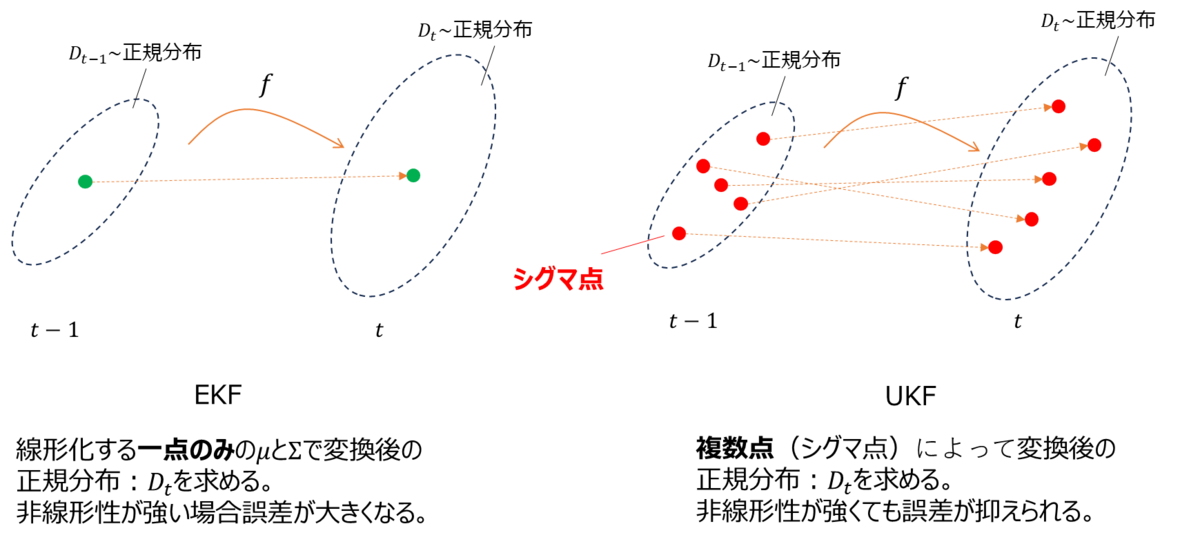
EKFは非線形変換を式(7),(8)で表したように更新前の状態量の周辺でTyalor展開して近似しました。これは図1の左側のように更新前の状態量一点の傾きのみで決まる変換が分布:$D_{t-1}$全体に適用されると仮定し、変換後の分布:$D_t$を計算します。しかし変換:$f$の非線形性が強い場合は展開した一点に適用される線形変換が分布:$D_{t-1}$のずれた点に対しては適用できず誤差が大きくなってしまうという問題が発生します。
そこでUKFでは決まったルールに則って抽出したサンプル複数個を$f$によって先に変換し、そのそれぞれの変換後の値を使って変換後の分布:$D_t$を求めます。この決まったルールによって抽出されたサンプル点を”シグマ点”といいます。非線形変換によって変換された点は正規分布には必ずしも従わないのですが、UKFでは変換後のシグマ点がもっとも従う正規分布を求めることで変換後の分布:$D_t$を決定します。
また、変換後のシグマ点を使って$D_t$を決定する際にすべてを等価に扱うわけではなく一般に中心に近いほど重みを付けて求めます。$D_t$を近似する際に注目する点により重みを付けた近似を行うことは自然な発想かと思います。 以下では、このシグマ点の抽出方法と重みについてと分布:$D_t$の導出手順について述べます。
シグマ点の抽出方法:
シグマ点の設定方法は無数に考えることができますが、その中でもより情報量が高くかつ満遍ない抽出方法を考えます。まずEKFでも代表点としている分布の平均点は含めるべき点であることは直感的にわかります。さらに平均点を中心に標準偏差の定数倍にした点を抽出します。分布を代表する方向を$L$個求めて図2のように各方向の+と-の方向にシグマ点を設定します。図2は$L=2$で合計5つのシグマ点を設定する例です。

一般に$L$個の方向でシグマ点をを取る場合に、$i=1,2,3,...,L$番目の方向のシグマ点:$\chi^{[i]}$は以下で表すことができます。
ここで${\bf \mu}$は平均点であり、$(\sqrt{(L+\lambda){\bf \Sigma }})_i$は以前のエントリーでも述べた対角化によって以下のように${ \bf U}$と${ \bf D}$に分解した行列の第$i$列です。
なので、$(\sqrt{(L+\lambda){\bf \Sigma }})_i$は上記式(17)・(18)によって導き出される${ \bf \sqrt{\Sigma}}$にスカラー倍の係数:$\sqrt{(L+\lambda)}$をかけたものになります。ここで$\lambda$は調整パラメータになります。
ところで、シグマ点を抽出するうえでは元の分布:$D_{t-1}$をなるべく代表する点を選びたいという目的がありました。そのために分布の拡がりがある方向に点をとっていくという方法をとります。これは主成分分析(Principle Component Analysis:PCA)において分散共分散行列を対角化することで主成分を求める手順にほかならず、それは式(17)そのものになります。なので、式(17)に登場する$\sqrt{D}$の成分を大きい順に並び変え、第1,2,...,L主成分の固有ベクトルこそが第$i$方向のシグマ点${\bf \chi}_{+}^{[i]},{\bf \chi}_{-}^{[i]}$の方向となる。
この変換された$2L+1$この点:${\bf \chi^{[0]}, \chi}_{+}^{[i]},{\bf \chi}_{-}^{[i]}$に重みを付けて平均と分散は以下のように計算されます。
ここで、$w_m^{[i]}$と$w_c^{[i]}$はそれぞれ平均と分散を求めるための合計が1となるような重み係数で以下のような式で表されます。これらの具体的な式の導出については本稿では割愛させて頂きますが、詳しくは参考文献[2]でも述べられているのでこちらを参照してください。
式(21)で$\alpha$と$\beta$は調整パラメータです。 以下でこれらの関係を用いた予測と更新の手続きでは、(17)と(18)式で抽出方向を求めたうえでシグマ点を決定し、式(21)で決定される重みを用いて式(19)と(20)で平均と分散を求めることを行います。
予測: 予測のステップ、つまり${\bf y_{t-1|t-1}}$から${\bf y_{t|t-1}}$を求める手順を整理します。なので、再帰的手続きによって${\bf \hat{y}_{t|t-1} }$と${ \bf \Sigma_{t|t-1}}$は求まっているものとします。 この下で式(17)と(18)のPCAの手続きによって抽出されたシグマ点を$s_i(i=1,2,3,...,2L+1)$とします。この時に式(1)の非線形関数$f$によって変換された点を$y_i$とします。
よって式(19)と(20)を用いることにより平均と分散は、
で求めることができます。
更新: 式(23)と(24)によって予測の${\bf \hat{y}}_{t|t-1}$と${\bf \Sigma}_{t|t-1}$が求まったのでこれからの更新の計算式を導出します。 予測と同様に、抽出されたシグマ点を$s_i(i=1,2,3,...,2L+1)$の式(2)の非線形関数$g$によって変換された点を$z_i$とします。
以前のエントリーでも述べたように、多変正規分布の条件付確率$X1|X2$はそれぞれの平均と共分散行列を用いて以下のようになります。
なので今求めたい${\bf y}_{t|t-1}|{\bf z}$はこの関係を使うことにより、式(27)-(32)で求める事が出来ます。
まとめ
非線形なモデルに対してカルマンフィルターを用いるための方法についてEKFとUKFについて説明しました。一般に非線形性が強い場合にはUKFが性能が良いとされています。 理論ばかりつらつらと説明してしまったので、次回のエントリーは今回までに説明したカルマンフィルターについて簡単なサンプルを実装してEKFやUKFの性能差を調べてみたいと思います。
参考記事
- カルマンフィルター過去解説記事
参考文献
[1] https://en.wikipedia.org/wiki/Kalman_filter
[2] "UKF(Unscented Kalman FIlter)って何?",(https://www.jstage.jst.go.jp/article/isciesci/50/7/50_KJ00004329717/_article/-char/ja/)