初めに
本エントリーでは、カルマンフィルターの入門として1次元のカルマンフィルタ、即ち状態量が1つのみの場合をまとめてみたいと思います。別エントリーで、一般の任意の数の状態量を持つカルマンフィルターについても説明しようと思いますが、式の意味を理解する上で行列の知識が必要になるのでまずは単純な一次式でモデルが表される1次元の場合でカルマンフィルターについての考え方について整理します。 前提知識として条件付き確率分布についての知識が必要となるので、その辺りこちらのエントリーにも記載しているので理解して貰ってから読んで頂けるとよいかと思います。 biocv.hateblo.jp
カルマンフィルターの概要を理解する上では、数値解析ソフトMatlabを開発しているMathWorks社が提供している以下の教材が非常に分かりやすかったのでお薦めです。
カルマンフィルターの目的
カルマンフィルターの目的は、直接観測が出来ない量について過去に得られている情報と現在得られている観測の情報を元に尤もらしい値を推定することです。具体的な例を挙げると、上記MathWorks社の教材内でも取り上げられているエンジンの内部温度を予測する例を考えます(図1)。
< 図1:エンジンの内部温度の予測

ある時刻$t$のエンジン内部温度:$y_t$を知りたいのですが、エンジンの内部は激しい化学反応が起きており直接温度計を仕掛けて測ることが出来ません。そこでエンジン容器を伝わって来た熱を容器の外側に取り付けた温度計によって観測した温度$Z_t$でエンジンの内部温度を予測する事を考えます。エンジン内部の温度は、時系列的に変化するので時刻$t$以前の温度の情報${y_1,y_2,...,y_{t-1}}$および温度を上げたり下げたり制御するための制御入力:$u_t$を予測に用いることができます。 既に説明したとおり、カルマンフィルターでは直接値を知ることが出来ない以上、具体的な確定値ではなくある程度不確からさをもった予測値をモデルによって求めるというスタンスをとります。具体的には、どの値がどのくらいの確からしさであり得そうなのか、つまり”確率分布”をモデルによって求めます。上記のエンジンの例では、内部温度を確率変数として扱うことで時刻$t$の$y_t$がどのような確率分布になっているかをモデルによって求めます。$y_t$が既知の分布であればそのパラメータ、例えば正規分布の場合は時刻$t$の平均と分散が求まれば良いです。
< 図2:確率変数としての状態量

カルマンフィルターのモデル
一般的な場合1次元の場合のカルマンフィルタをモデル化し、モデルを用いて状態量を推定するステップについて述べて、その際重要となるカルマンゲインについても導出します。 1次元の状態量:$y_t$が一つ前の時刻$t-1$の状態量:$y_{t-1}$ と制御入力:$u_t$によって決まる状態遷移モデルを考えます。状態量とは一般に直接観測できない情報であり、カルマンフィルターの目的は以前の情報と現在得られている観測情報:$z_t$から状態量$y_t$を推定することです。グラフで表すと図3のようになります。
< 図3:状態遷移モデル

1次元のカルマンフィルターでは$y_t$が$y_{t-1}$と$u_t$の1次の式、および$z_t$が$y_t$の1次の式で表される以下のような式の関係で状態遷移が表される場合を考えます。式(1)を1つ前の状態から今の状態を”予測する”モデルとして「予測モデル:Prediction Model」といい、図3において赤い矢印で表されるエッジです。式(2)を得られている状態と観測情報の関係を表すモデルとして「観測モデル:Observation Model」といい、図3において緑の矢印で表されるエッジです。また、それぞれのモデルには誤差$\epsilon_t$と$\eta_t$がありそれぞれ平均が0で分散が$R^2,Q^2$の正規分布であるとします。 $y_t$,$u_t$,$z_t$と$\epsilon_t$,$\eta_t$はtによらず独立であるとします。
$$ y_t=a_t y_{t-1} + b_t u_t + \epsilon_t \tag{1} $$
$$ z_t = h_t y_t + c_t + \eta_t \tag{2} $$
$$ \epsilon_t \sim N(0, R^2) \tag{3} $$
$$ \eta_t \sim N(0, Q^2) \tag{4} $$
ここで時刻$t$において得られている情報:$I_t$を以下の様に定義します。 $$ I_t \equiv \{Z_1,Z_2,Z_3,...,Z_t,u_1,u_2,...,u_t\} \tag{5} $$ つまり$I_t$は時刻$t$の時点で得られている情報の全てで、具体的には$t$以前の全ての観測と制御入力です。この情報:$I_t$を用いることによって図3のグラフは図4のように単純化することができ、$y_t$は一つ前の時刻$t_1$までに得た情報:$I_{t-1}$とその時刻の制御入力$u_t$によって決まることを表しています。
< 図4:情報量を使った簡略化

カルマンフィルターでは状態量$y_t$を確率変数として扱い、ここでは正規分布に従うとします。
予測モデル
以上で述べたモデルを用いて$t-1$までに得ている情報から、$t$の状態を予測する予測のモデルを書き下します。具体的には、$y_{t-1}$の分布から$y_t$の分布を求めるが正規分布を仮定しているので、時刻$t$の平均と分散が時刻$t-1$の平均と分散によってどう表されるかを考えれば良いです。
$$ \hat{y}_{t|t-1}=E[y_t|I_{t-1}, u_t] \tag{6} $$
$$ \Sigma_{t|t-1} = Var[y_t|I_{t-1},u_t] \tag{7} $$
式(1)-(4)を使って計算すると平均は、
分散は、
まとめると予測モデルは式(10)になります。
更新モデル
予測モデルでは、時刻$t-1$までの情報$I_{t-1}$を使って1つ先の時刻:$t$の状態$y_t$の予測値:$y_{t|t-1}$の分布を求めました。更新モデルでは、時刻$t$に得られている情報の全て:$I_t$を使って更に精度を高めるべく、予測値:$y_{t|t-1}$の分布から更新値:$y_{t|t}$の分布を求めます。 下記の式(11),(12)によって$y_{t|t}$の平均と分散を更新値を得ることが出来ます。
$$ \hat{y}_{t|t}=E[y_t|I_{t}] \tag{11} $$
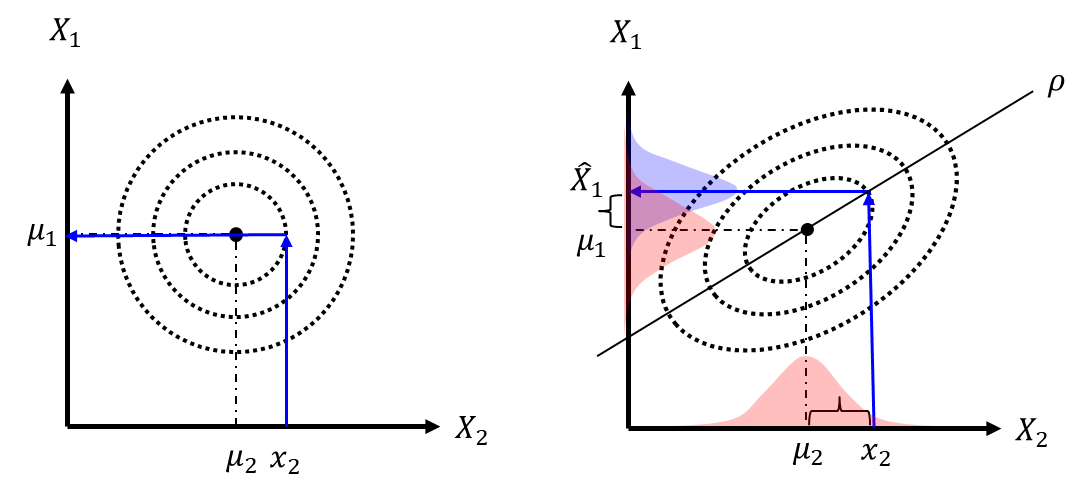
$$ \Sigma_{t|t} = Var[y_t|I_t] \tag{12} $$ これらを展開して、予測値$y_{t|t-1}$から$y_{t|t}$を求める更新式を導き出します。それには冒頭で述べた別エントリーにて紹介した条件付き確率の平均・分散の関係を用います。 具体的には、2変数正規分布に従う確率変数$\bf{X}=(X_1,X_2)$について、$X_2$の実現値$x_2$が得られた時の条件付確率分布: $X_1|X_2$は以下で表されるのでこの関係式を用います。ここで$\rho$は$X_1$と$X_2$の相関係数です。
式(13)の関係式を用いて式(11)と式(12)を展開します。 まず平均$\hat{y}_{t|t}$は、
式(15)における相関係数$\rho$は以下になります。 $$ \rho = \frac{Cov(y_{t|t-1},z_t)}{\sqrt{Var[y_{t|t-1}]} \sqrt{Var[z_t]}} \tag{16} $$
式(14)の第二項の係数がカルマンゲイン:$K_t$でありこれを具体的に計算します。 まず分母となる観測$z_t$の分散$Var[z_t]$は、
となります。 よって$K_t$は、
となります。 分散$\Sigma_{t|t-1}$は、式(16)と式(18)を用いるとカルマンゲイン:$K_t$を用いて
まとめると更新モデルは式(20)になります。
更新モデルの直感的理解
式(16)と式(18)からカルマンゲイン$K_t$は以下のようにも書ける。 $$ K_t = \rho \frac{\sqrt{Var[y_{t|t-1}]}}{\sqrt{Var[z_t]}} \tag{21} $$ これは、予測と観測の相関係数に対して互いの不確かさの標準偏差の比を重みにかけた値が、フィルタリングの係数になっていることを表しています。 $\rho$は時刻$t$までの観測$z_t$と予測$y_t$の相関であり、何ら相関のない観測が得られている場合は0に近く極めて相関の高い観測が得られている場合は1に近づきます。 標準偏差の比はそれぞれの分布の確からしさで正規化する役割をしていて、観測の標準偏差が分母なので観測があまり確からしくなければ更新は小さくなり、確かであれば大きくなることを表しています。 逆に分子の予測の標準偏差が小さい、即ち十分に確度が高く予測できている状態においてはあまり観測は反映されず、更新は小さくなることを表しています。
まとめ
カルマンフィルターの目的について確認し、さらに1次元のカルマンフィルターつまり状態量が1つのみの場合のカルマンフィルターについて正規性を仮定した下で予測と更新のモデル式(10)と(20)を導出しました。カルマンフィルターを何となくではなく、実感をもって理解するにはこの式の展開を自分で一度やってみるところは避けて通れないところなのかなと思っています。本エントリーでは正規性を仮定して導出を行いましたが、より緩い制約としての不偏性さえ満たせばカルマンフィルターとしては成立します。そちらの導出に関しては、下記に上げる参考書等をご確認下さい。 実用上の問題では、複数の値を持つ多次元の状態量を扱う必要がある場合が殆どなので、別エントリーにて一般の多次元のカルマンフィルターについても解説したいと思います。
参考
- 経済・ファイナンスのための カルマンフィルター入門 (統計ライブラリー, 森平 爽一郎著, 2019/2/6)
- MathWorks "カルマンフィルターとは?"(https://jp.mathworks.com/discovery/kalman-filter.html)