はじめに
ある確率変数の実現値が分かった時の別の確率変数の確率分布を条件付確率分布という。本エントリーでは、多変数正規分布においての条件付確率分布・期待値・分散について、式の導出やその意味について考察をしたので備忘録も兼ねて紹介しようと思う。別エントリーにて書く予定のカルマンフィルターを理解する上で、条件付確率分布の理解はその土台となる。条件付期待値や分散の式が持つ意味合いについてしっかりと理解すると、カルマンフィルタの更新式の理解も深まると思います。そのあたり自分と同様不安な方は、よりクリアにして頂ければ幸いです。
2変数正規分布の条件付き確率
2変数正規分布に従う確率変数$\bf{X}=(X_1,X_2)$がある。
$\mu_1$と$\mu_2$および$\sigma_1$と$\sigma_2$は$X_1$と$X_2$の期待値・標準偏差であり、$\rho$は相関係数である。 この時、周辺分布$X_2$の分布ついても正規分布となる。
$$ \bf{X_2} \sim N(\mu_2,{\sigma_2}^2) \tag{5} $$
以上のもとで$X_2$の実現値$x_2$が得られた時の条件付確率分布: $X_1|X_2$について考える。$X_1|X_2$の確率密度関数$f(x_1|x_2)$は以下の式によって与えられる。
$$ f(x_1|x_2)=\frac{f(x_1,x_2)}{f(x_2)} \tag{6} $$
式(1)と(5)の確率密度関数$f(x_1,x_2)$と$f(x_2)$を具体的に書き下すと、
となる。 式(3)の成分を用いて$\sqrt{|\Sigma|}$を計算すると、
$$ \sqrt{|\Sigma|} = \sqrt{1-{\rho}^2}\sigma_1 \sigma_2 \tag{9} $$
となる。 また、式(7)の指数部分も同様に具体的に計算すると、
これより、式(6)は、
となる。 よって、$X_2=x_2$の実現値が得られたときの$X_1|X_2$は以下の平均と分散を持つ正規分布に従うことがわかる。
式(4)を用いると式(12)のようにも書ける。
条件付確率の期待値・分散の意味
式(12)の結果の意味について考えてみる。まずは分散${\sigma_1}^2 (1-{\rho}^2)$について、相関係数$\rho$が$-1 \leq \rho \leq 1$であることに注意すると、$X_2=x_2$の観測が得られることによって必ず$X_1|X_2 = x_2$の分散は小さくなるか変化しないことを表している。これが意味するところを感覚的に捉えれば、$X_1$と$X_2$に何かしらの相関がある場合に、$X_2$に何かしらの情報が得られた際、それが相関係数$\rho$を介して伝搬して$X_1$の情報に影響を与え、予測の確度を高める、ということである。 東京の気温と山梨の気温を考えたときに、これらは地理的に近いため一定の相関を有していると考えられる。つまり、ある日の東京の気温($X_1$)の期待値の確度(分散)は、山梨の気温($X_2$)の実測値を知らない場合より、知っている場合のほうが確度が高まる。より具体的には、山梨の気温が高かった場合には、それを知る前よりも東京の気温の予測値を高い方向へ更新し、さらに更新前よりもその予測に対しての自信が高くなる、ということを意味している。これは普段我々が行っている推測と何ら変わらず、極自然に感じられると思う。 実際に式(11)が意味するところはそういうことで、図を書いてみると図1のようになる。
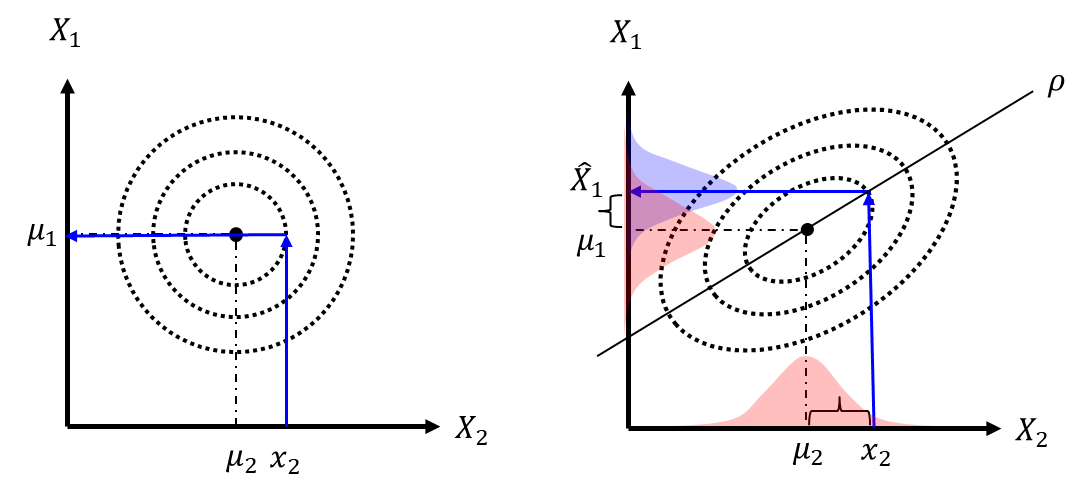
期待値:$\mu_1 + \rho \frac{\sigma_1}{\sigma_2}(x_2-\mu_2)$の意味についても図1を眺めることによって雰囲気がつかめると思う。元々思っていた$X_2$の予測値:$\mu_2$に対して実際得られた実現値:$x_2$との差、$(x_2-\mu_2)$に$\rho \frac{\sigma_1}{\sigma_2}$の影響度合いをかけて$\mu_1$に足すことで$X_2=x_2$を知ることによる$X_1$の予測値を更新している。ここで傾き$\rho \frac{\sigma_1}{\sigma_2}$は相関係数:$\rho$に$X_1$と$X_2$の標準偏差の比をかけたものになっている。$X_1$と$X_2$に全く相関がない場合は、$\rho=0$となり、図1左側のようになる。この場合は、$X_2=x_2$を知ったところで何らこれらの変数には関係がないので$X_1$の予測は更新されない、ということになる。標準偏差の比:$\frac{\sigma_1}{\sigma_2}$については、$X_2$の標準偏差:$\sigma_2$が小さい、即ち知る情報の確度が高いほど更新が大きくなり、また$X_1$の標準偏差:$\sigma_1$が大きいほど、予測の確度が低いほど更新が大きくなることを表している。確度が高い$X_2$の情報を得るほど$X_1$の予測が更新され、$X_1$の予測の確度がもともと高ければ、$X_2$の情報が得られてもあまり更新しない、というのも一般的な感覚からも受け入れ易いと思う。
まとめ
正規分布の条件付き期待値と分散についてまとめました。2変数の場合の式を導出し、導き出される期待値と分散についてその意味を考えてみました。式(12)・(13)が意味するところをしっかりと理解するところが様々な応用において重要かと思います。途中式(9),(10)の展開などは省略しましたが、単純な展開なので記事で長々と紹介するよりも、気になる方は手を動かして納得して頂くのがよいかと思います。 カルマンフィルタでは時系列のデータを扱い、過去の情報からの予測を現在得られる観測によって更新し続けます。この時の予測の更新に式(13)が登場します。なのでカルマンフィルタを理解するという特定の目的においても本記事で書いた内容は重要だと思います。カルマンフィルタについてはまた別エントリーで記載する予定です。
以上、お読み頂きありがとうございました。
参考文献
- 現代数理統計学の基礎(共立講座 数学の魅力 11)(2017/4/11),久保川 達也 (著)